Rapidly Developing an AI Assistant to query a knowledge base with RAG using Azure OpenAI: A Proof-of-Concept Guide
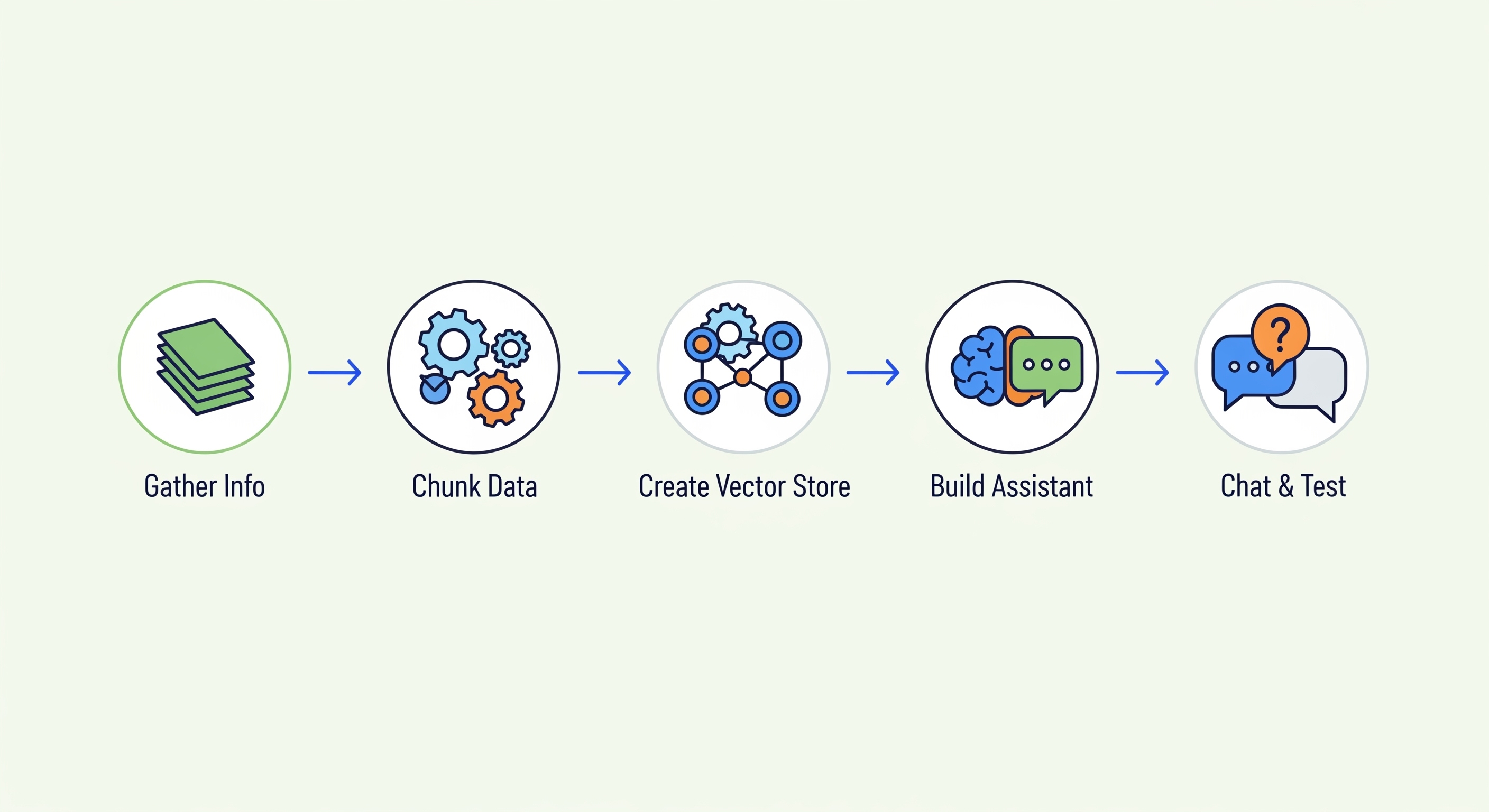
The ability to converse with proprietary knowledge bases represents a significant advancement in information retrieval and operational efficiency. This guide outlines a streamlined process for rapidly developing a proof-of-concept AI Assistant using Retrieval Augmented Generation (RAG) with Azure OpenAI, enabling users to query custom information sources effectively.
The objective is to quickly establish an AI Assistant that leverages your organisation’s specific information to provide informed responses.
Step 0: Identify the Target Business Process and Collate Structured Information
Before commencing development, clearly define the information-driven business process you aim to enhance (e.g., streamlining responses to frequently asked questions, accelerating new employee onboarding, providing immediate access to policy documentation). Subsequently, gather the most structured and relevant information pertaining to this process.
Step 1: Assemble the Knowledge Base Information
Compile all documents and data that will constitute the AI’s knowledge base. This information will be transformed into a vector database.
(A lay description of a vector database: Consider a vector database as an advanced indexing system for your information. Instead of merely storing files by name or keywords, it comprehends the semantic meaning and context of the text within. When a query is posed, it searches for information that is semantically similar—related in meaning—rather than just matching keywords. This is achieved by converting text into numerical representations called ‘vectors’, allowing the AI to retrieve the most pertinent information even if the query uses different terminology from the source documents.)
Step 2: Convert Information to a Simple, Structured Text Format
For this initial development phase, transform your information into plain text files (.txt). Employ a simple, consistent structure that can be easily parsed by a script. For instance, a question-and-answer document could be formatted as:
Q: What is our organisation's standard refund procedure?
A: Our standard refund procedure dictates that...
Q: How can an employee request a password reset?
A: To request a password reset, employees should follow these steps...
A clear and straightforward structure simplifies programmatic processing.
A clear and straightforward structure simplifies programmatic processing.
Step 3: Investigate an Optimal Chunking Strategy
“Chunking” involves segmenting larger texts into smaller, more manageable units. This is beneficial as AI models have limitations on input text length, and smaller, semantically coherent chunks generally yield more precise retrieval results.
For a proof-of-concept, consider chunking by paragraph, logical sections under headings, or distinct question-and-answer pairs. The primary aim is to create logical divisions in the information without excessive initial complexity.
Step 4: Develop a Python Script for Chunking
A Python script will be required to read your input text files and implement the chosen chunking strategy.
- Recommendation: Utilise Generative AI tools (e.g., Azure OpenAI’s playground, GitHub Copilot) to assist in drafting this script.
- Example Prompt: “Generate a Python script to read a text file, segment its content based on double line breaks (thereby separating paragraphs), and save each paragraph as an individual text file into a specified output directory named ‘output_chunks’.”
- Iteration on this script will likely be necessary to align with your specific file structures and chunking requirements.
Step 5: Execute the Chunking Script
Run the developed Python script on your source information files. This will produce a collection of smaller text files representing your chunked knowledge base.
Step 6: Create a Vector Store in Azure OpenAI and Upload Chunked Documents
Azure OpenAI’s newer features facilitate this process:
- Navigate to your Azure OpenAI Studio.
- Locate the “Vector Stores” functionality (associated with the Assistants API v2 features).
- Initiate the creation of a new Vector Store, assigning a descriptive name (e.g.,
InternalPolicyVS). - Upload your previously generated chunked text files into this Vector Store. Azure OpenAI will manage the embedding process.
Step 7: Create an Azure OpenAI Assistant and Link the Vector Store
- Within the Azure OpenAI Studio, proceed to the “Assistants” section.
- Create a new Assistant.
- Instructions (System Prompt): Provide a foundational instruction, such as: “You are an AI assistant. Your responses must be based solely on the information contained within the documents provided to you.”
- Enable File Search/Retrieval Tool: In the Assistant’s configuration under “Tools,” activate the “File Search” (or “Retrieval”) capability.
- Attach Vector Store: Link the Vector Store created in Step 6. This is typically done within the
Tool resourcessection for File Search, referencing your Vector Store’s ID (e.g.,InternalPolicyVS).
Step 8: Crucial - Explicitly Direct the Assistant to Use the Vector Store in Queries
For initial testing and to ensure the RAG mechanism is being invoked, it is vital to be explicit in your queries:
- Example Phrasing: “Using only the information in vector store
InternalPolicyVS, what is the procedure for X?” or “According to the provided documents inInternalPolicyVS, detail Y.” - Substitute
InternalPolicyVSwith the actual name or identifier of your vector store. - This direct instruction encourages the Assistant to prioritise retrieval from your custom knowledge base.
Step 9: Test and Validate Outputs
Pose questions to the Assistant for which you know the correct answers (based on your source documents). Evaluate:
- Accuracy and relevance of the responses.
- Whether the Assistant correctly references the source documents (if citation capabilities are configured and enabled).
- The Assistant’s behaviour when information is not present in the knowledge base (does it state so, or does it generate speculative information?).
Step 10: User Training and Process Refinement
Upon validating the proof-of-concept:
- Demonstrate its capabilities to potential end-users.
- Solicit feedback for improvements.
- Assess how this AI Assistant can genuinely enhance the business process identified in Step 0.
- Subsequently, you can iterate on data quality, chunking strategies, system prompts, and overall solution architecture.
This streamlined methodology allows for rapid validation of RAG concepts using Azure OpenAI, providing a tangible demonstration of how AI can interact with specific knowledge bases before committing to more extensive, production-grade development efforts.