Garbage In, Garbage Out: Why Data Hygiene is the Secret to RAG Precision
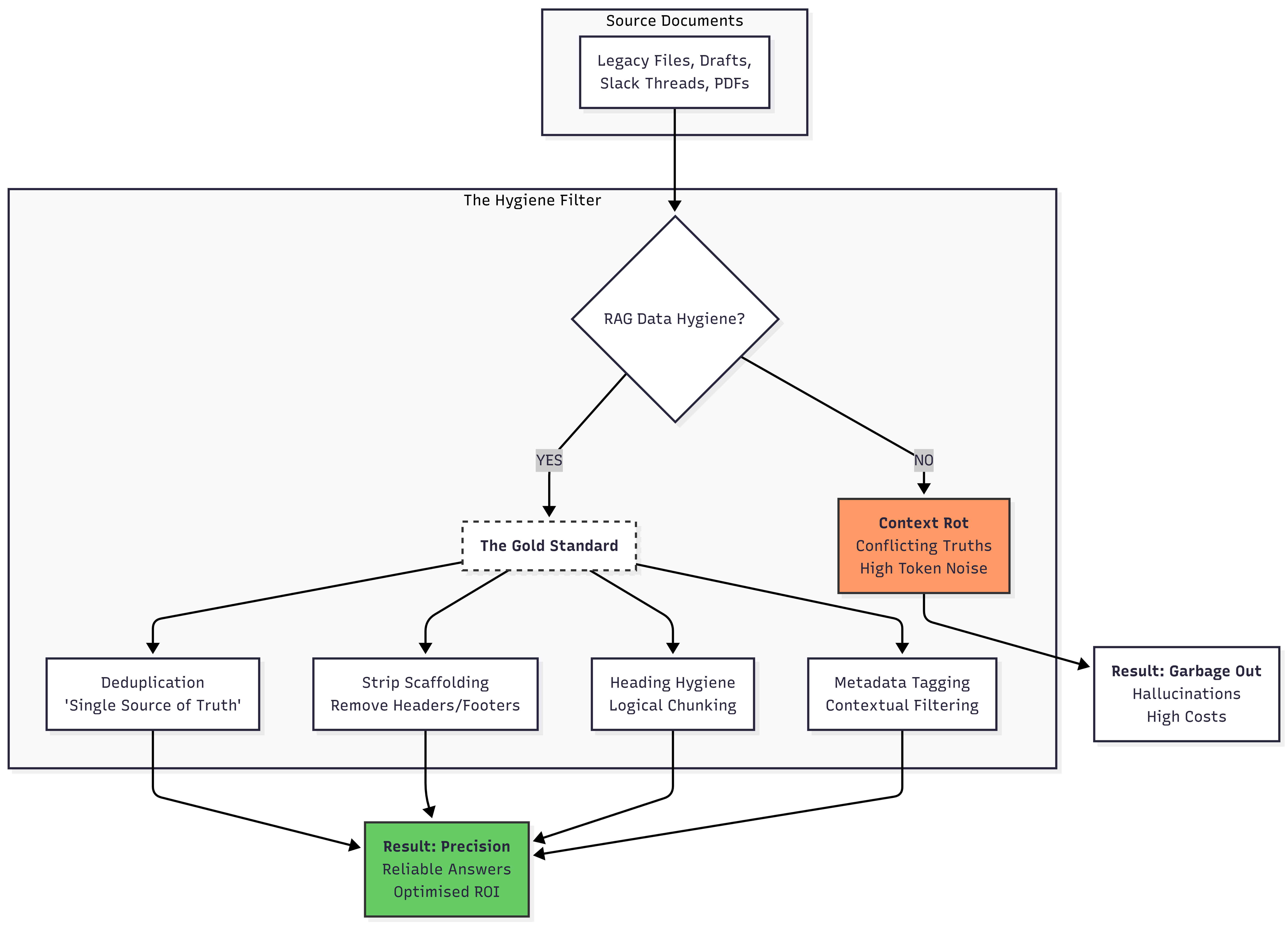
In the race to deploy AI, specifically Retrieval-Augmented Generation (RAG) systems, we often see organisations engage in “prompt stuffing”—cramming every PDF, Slack thread, and legacy document into a vector database and hoping that the context window will resolve the ambiguity.
The reality, as I discovered working on client project, is that if you treat your vector database like a digital dumping ground, your AI will behave like a confused intern. It results in “Context Rot”: high token costs, contradictory answers, and an LLM that is effectively hallucinating because it cannot distinguish between a 2018 draft and a 2025 final policy.
In the AI era, Data Hygiene isn’t just a “nice-to-have”; it is the most powerful lever for accuracy and cost control. Better information going in doesn’t just save money; it creates a level of search precision that makes the AI feel like a true subject matter expert.
Here are four simple, non-technical strategies we used to optimise our AI Knowledge Base and ensure our “Project Brain” remained a high-performance asset.
1. The “Gold Standard” Rule (Deduplication)
Project folders are notoriously messy. You likely have Business_Requirements_v1, v2, and v2_FINAL_FINAL.
The AI Risk: If all versions are ingested, the AI has no way of knowing which is the current “truth”. It might retrieve a 2023 constraint that was scrapped in 2025.
The Fix: Before ingestion, audit your source folders. Only “Gold Standard” documents—the authoritative, current versions—should be fed to the AI. Deduplicating your source data before it hits the database removes retrieval conflict and is the single most effective way to lower token costs.
2. Stripping the “Scaffolding” (Noise Reduction)
Standard project documents are often 20% content and 80% “packaging”.
The AI Risk: Headers, footers, lengthy Tables of Contents, and standard legal boilerplate take up valuable space in the LLM’s context window. You are effectively paying to send the words “Confidential - Do Not Distribute” to the AI 500 times a day.
The Fix: Clean your documents. AI doesn’t need your legal headers or page numbers. Cleaning these out ensures every token in the prompt is pure, high-value information.
3. Enforcing Heading Hygiene
AI models don’t “read” like humans, but they thrive on structure.
The AI Risk: A 50-page wall of text with no clear headings is impossible to “chunk” correctly. The system might split a vital requirement halfway through a sentence.
The Fix: Ensure every document uses proper Heading Styles (H1, H2, H3). This logical structure acts as a roadmap, allowing for cleaner “chunking”. This ensures the system keeps related ideas together, leading to much sharper search results.
4. The Power of Metadata (Contextual Tagging)
Sometimes, the AI needs to know where a piece of information came from to understand its weight.
The Fix: Tag your documents with simple attributes before ingestion: Phase: Discovery, Squad: Backend, Type: Requirement. This allows the system to filter out irrelevant information before it even starts the search, ensuring the AI only looks at the data that matters for that specific query.
Better In = Better Out
By shifting our focus from quantity to quality, we didn’t just reduce our token spend; we saw a marked increase in the reliability of the AI’s answers. The lesson is clear: Data Architecture is the foundation of the AI era. If your underlying data is messy, no amount of prompt engineering can save your ROI.
In my next post, I’ll be diving into the technical solutions—from semantic chunking to re-ranking—that we used to further optimise a RAG solution.